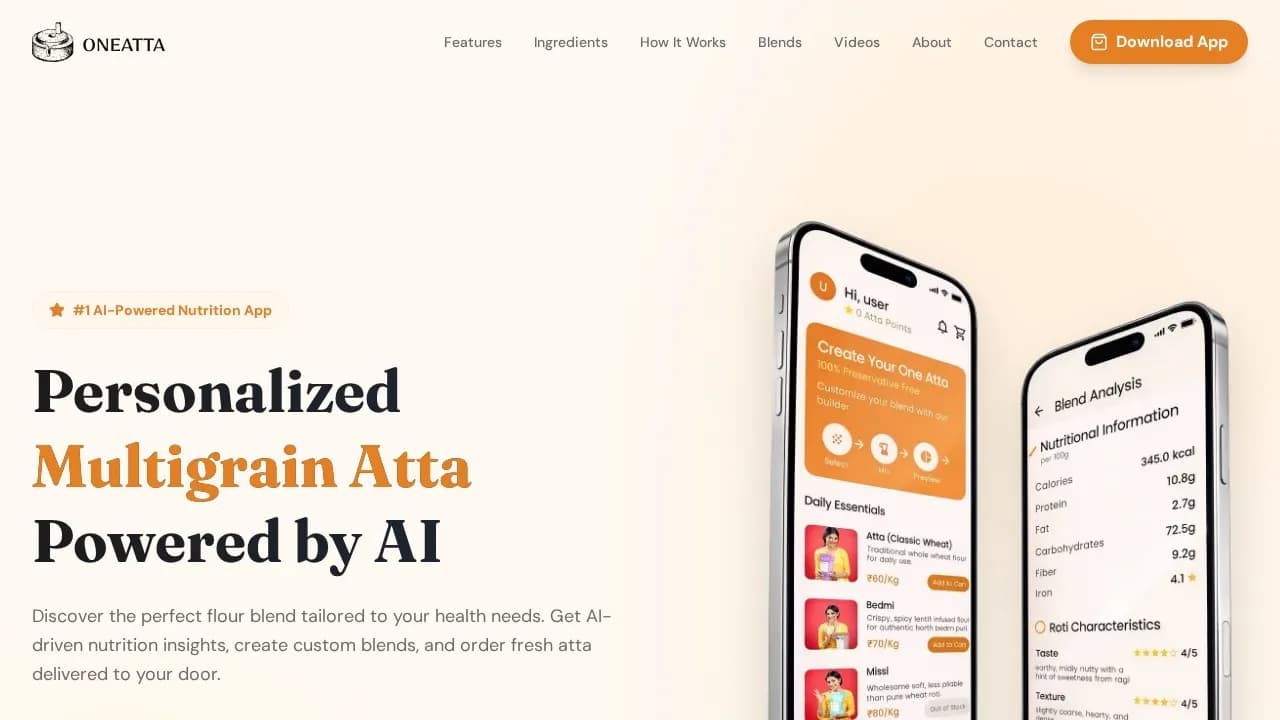
CASE 01Production
Live
CI/CD pipeline
Caratly
Automated deployment pipeline — version-controlled releases, staging environment, production promotion process. Fine-grained repository access for a distributed development workflow.
- Version-controlled releases with automated build + test
- Staging → production promotion with rollback strategy
- Fine-grained repo access for distributed contributors